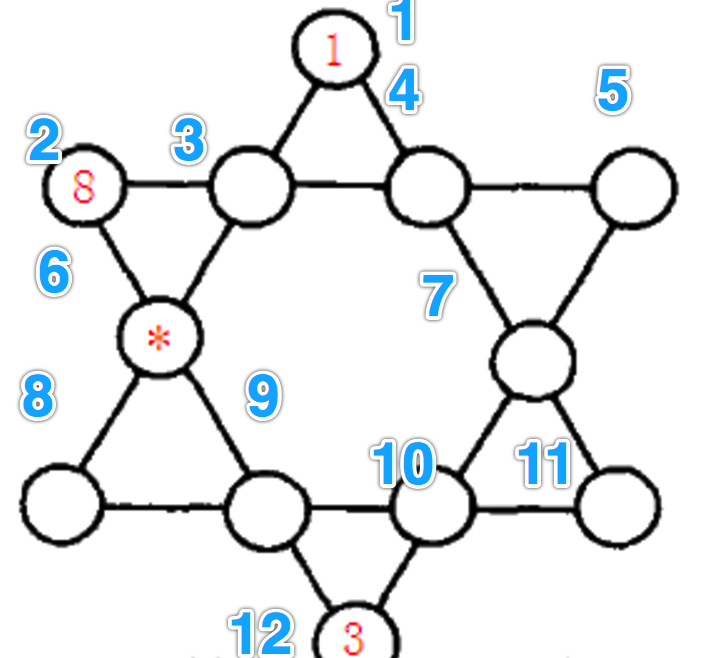
最短路径
- 单源最短路径:计算源点到其他各顶点的最短路径的长度
- 全局最短路径:图中任意两点的最短路径
- Dijkstra、Bellman-Ford、SPFA求单源最短路径
- Floyed可以求全局最短路径,但是效率比较低
- SPFA算法是Bellman-Ford算法的队列优化
- Dijkstra算法不能求带负权边的最短路径,而SPFA算法、Bellman-Ford算法、Floyd-Warshall可以求带负权边的最短路径。
- Bellman-Ford算法的核心代码只有4行,Floyd-Warshall算法的核心代码只有5行。
- 深度优先遍历可以求一个点到另一个点的最短路径的长度
Dijkstra算法
|
1 2 3 4 5 6 7 8 9 10 11 |
Dijkstra() { 初始化; for(循环n次) { u = 使dis[u]最小的还未被访问的顶点的编号; 记u为确定值; for(从u出发能到达的所有顶点v){ if(v未被访问 && 以u为中介点使s到顶点v的最短距离更优) 优化dis[v]; } } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
//邻接矩阵 int n, e[maxv][maxv]; int dis[maxv], pre[maxv];// pre用来标注当前结点的前一个结点 bool vis[maxv] = {false}; void Dijkstra(int s) { fill(dis, dis + maxv, inf); dis[s] = 0; for(int i = 0; i < n; i++) pre[i] = i; //初始状态设每个点的前驱为自身 for(int i = 0; i < n; i++) { int u = -1, minn = inf; for(int j = 0; j < n; j++) { if(visit[j] == false && dis[j] < minn) { u = j; minn = dis[j]; } } if(u == -1) return; visit[u] = true; for(int v = 0; v < n; v++) { if(visit[v] == false && e[u][v] != inf && dis[u] + e[u][v] < dis[v]) { dis[v] = dis[u] + e[u][v]; pre[v] = u; // pre用来标注当前结点的前一个结点 } } } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
//邻接表 struct node { int v, dis; } vector<node> e[maxv]; int n; int dis[maxv], pre[maxv];// pre用来标注当前结点的前一个结点 bool visit[maxv] = {false}; for(int i = 0; i < n; i++) pre[i] = i; //初始状态设每个点的前驱为自身 void Dijkstra(int s) { fill(dis, dis + maxv, inf); dis[s] = 0; for(int i = 0; i < n; i++) { int u = -1, minn = inf; for(int j = 0; j < n; j++) { if(visit[j] == false && dis[j] < minn) { u = j; minn = dis[j]; } } if(u == -1) return ; visit[u] = true; for(int j = 0; j < e[u].size(); j++) { int v = e[u][j].v; if(visit[v] == false && dis[u] + e[u][j].dis < dis[v]) { dis[v] = dis[u] + e[u][j].dis; pre[v] = u; } } } } |
|
1 2 3 4 5 6 7 8 |
void dfs(int s, int v) { if(v == s) { printf("%d\n", s); return ; } dfs(s, pre[v]); printf("%d\n", v); } |
- 三种附加考法:第一标尺是距离,如果距离相等的时候,新增第二标尺
- 新增边权(第二标尺),要求在最短路径有多条时要求路径上的花费之和最小
12345678910for(int v = 0; v < n; v++) { //重写v的for循环if(visit[v] == false && e[u][v] != inf) {if(dis[u] + e[u][v] < dis[v]) {dis[v] = dis[u] + e[u][v];c[v] = c[u] + cost[u][v];}else if(dis[u] + e[u][v] == dis[v] && c[u] + cost[u][v] < c[v]) {c[v] = c[u] + cost[u][v];}}}- 给定每个点的点权(第二标尺),要求在最短路径上有多条时要求路径上的点权之和最大
12345678910for(int v = 0; v < n; v++) {if(visit[v] == false && e[u][v] != inf) {if(dis[u] + e[u][v] < dis[v]) {dis[v] = dis[u] + e[u][v];w[v] = w[u] + weight[v];}else if(dis[u] + e[u][v] == dis[v] && w[u] + weight[v] > w[v]) {w[v] = w[u] + weight[v];}}}- 直接问有多少条最短路径
增加一个数组num[],num[s] = 1,其余num[u] = 0,表示从起点s到达顶点u的最短路径的条数为num[u]
12345678910for(int v = 0; v < n; v++) {if(visit[v] == false && e[u][v] != inf) {if(dis[u] + e[u][v] < dis[v]) {dis[v] = dis[u] + e[u][v];num[u] = num[v];}else if(dis[u] + e[u][v] == dis[v]) {num[v] = num[v] + num[u];}}}
- 例子:比如说又要路径最短,又要点权权值最大,而且还要输出个数,而且还要输出路径
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
for(int v = 0; v < n; v++) { if(visit[v] == false && e[u][v] != inf) { if(dis[u] + e[u][v] < dis[v]) { dis[v] = dis[u] + e[u][v]; num[v] = num[u]; w[v] = w[u] + weight[v]; pre[v] = u; } else if(dis[u] + e[u][v] == dis[v]) { num[v] = num[v] + num[u]; if(w[u] + weight[v] > w[v]) { w[v] = w[u] + weight[v]; pre[v] = u; } } } } void printPath(int v) { if(v == s) { printf("%d", v); return ; } printPath(pre[v]); printf("%d ", v); } |
- of course, 可以不用这么麻烦,用Dijkstra求最短路径和pre数组,然后用深度优先遍历来获取想知道的一切,包括点权最大,边权最大,路径个数,路径
- 因为可能有多条路径,所以Dijkstra部分的pre数组使用
vector<int> pre[maxv]; -
12345678//Dijkstra部分if(dis[u] + e[u][v] < dis[v]) {dis[v] = dis[u] + e[u][v];pre[v].clear();pre[v].push_back(u);} else if(dis[i] + e[u] == dis[v]) {pre[v].push_back(u);}
- 既然已经求得pre数组,就知道了所有的最短路径,然后要做的就是用dfs遍历所有最短路径,找出一条使第二标尺最优的路径
-
12345678910111213141516171819int optvalue;vector<int> pre[maxv];vector<int> path, temppath;void dfs(int v) { // v为当前访问结点if(v == start) {temppath.push_back(v);int value = 路径temppath上的value值;if(value 优于 optvalue) {optvalue = value;path = temppath;}temppath.pop_back();return ;}temppath.push_back(v);for(int i = 0; i < pre[v].size(); i++)dfs(pre[v][i]);temppath.pop_back();}
- 解释:
- 对于递归边界而言,如果当前访问的结点是叶子结点(就是路径的开始结点),那么说明到达了递归边界,把v压入temppath,temppath里面就保存了一条完整的路径。如果计算得到的当前的value大于最大值,就path = temppath,然后把temppath的最后一个结点弹出,return ;
- 对于递归式而言,每一次都是把当前访问的结点压入,然后找他的pre[v][i],进行递归,递归完毕后弹出最后一个结点
- 计算当前temppath边权或者点权之和的代码:
-
123456789101112// 边权之和int value = 0;for(int i = tempptah.size() - 1; i > 0; i--) {int id = temppath[i], idnext = temppath[i - 1];value += v[id][idnext];}// 点权之和int value = 0;for(int i = temppath.size(); i >= 0; i--) {int id = temppath[i];value += w[id];}
- 计算路径直接在Dijkstra部分写就可以
- 例子:计算最短距离的路径和最小花费
-
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374#include <cstdio>#include <algorithm>#include <vector>using namespace std;int n, m, s, d;int e[510][510], dis[510], cost[510][510];vector<int> pre[510];bool visit[510];const int inf = 99999999;vector<int> path, temppath;int mincost = inf;void dfs(int v) {if(v == s) {temppath.push_back(v);int tempcost = 0;for(int i = temppath.size() - 1; i > 0; i--) {int id = temppath[i], nextid = temppath[i-1];tempcost += cost[id][nextid];}if(tempcost < mincost) {mincost = tempcost;path = temppath;}temppath.pop_back();return ;}temppath.push_back(v);for(int i = 0; i < pre[v].size(); i++)dfs(pre[v][i]);temppath.pop_back();}int main() {fill(e[0], e[0] + 510 * 510, inf);fill(dis, dis + 510, inf);scanf("%d%d%d%d", &n, &m, &s, &d);for(int i = 0; i < m; i++) {int a, b;scanf("%d%d", &a, &b);scanf("%d", &e[a][b]);e[b][a] = e[a][b];scanf("%d", &cost[a][b]);cost[b][a] = cost[a][b];}pre[s].push_back(s);dis[s] = 0;for(int i = 0; i < n; i++) {int u = -1, minn = inf;for(int j = 0; j < n; j++) {if(visit[j] == false && dis[j] < minn) {u = j;minn = j;}}if(u == -1) break;visit[u] = true;for(int v = 0; v < n; v++) {if(visit[v] == false && e[u][v] != inf) {if(dis[v] > dis[u] + e[u][v]) {dis[v] = dis[u] + e[u][v];pre[v].clear();pre[v].push_back(u);} else if(dis[v] == dis[u] + e[u][v]) {pre[v].push_back(u);}}}}dfs(d);for(int i = path.size() - 1; i >= 0; i--)printf("%d ", path[i]);printf("%d %d", dis[d], mincost);return 0;}//注意路径path因为是从末端一直压入push_back到path里面的,所以要输出路径的时候倒着输出