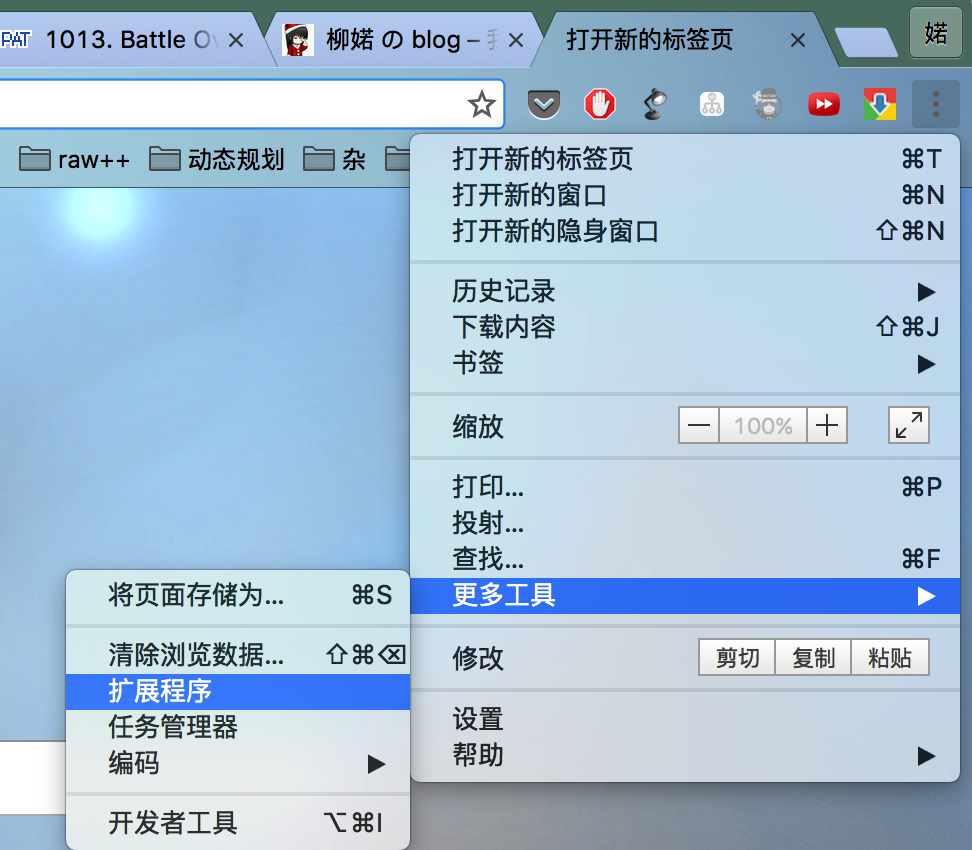
A long-distance telephone company charges its customers by the following rules:
Making a long-distance call costs a certain amount per minute, depending on the time of day when the call is made. When a customer starts connecting a long-distance call, the time will be recorded, and so will be the time when the customer hangs up the phone. Every calendar month, a bill is sent to the customer for each minute called (at a rate determined by the time of day). Your job is to prepare the bills for each month, given a set of phone call records.
Input Specification:
Each input file contains one test case. Each case has two parts: the rate structure, and the phone call records.
The rate structure consists of a line with 24 non-negative integers denoting the toll (cents/minute) from 00:00 – 01:00, the toll from 01:00 – 02:00, and so on for each hour in the day.
The next line contains a positive number N (<= 1000), followed by N lines of records. Each phone call record consists of the name of the customer (string of up to 20 characters without space), the time and date (mm:dd:hh:mm), and the word “on-line” or “off-line”.
For each test case, all dates will be within a single month. Each “on-line” record is paired with the chronologically next record for the same customer provided it is an “off-line” record. Any “on-line” records that are not paired with an “off-line” record are ignored, as are “off-line” records not paired with an “on-line” record. It is guaranteed that at least one call is well paired in the input. You may assume that no two records for the same customer have the same time. Times are recorded using a 24-hour clock.
Output Specification:
For each test case, you must print a phone bill for each customer.
Bills must be printed in alphabetical order of customers’ names. For each customer, first print in a line the name of the customer and the month of the bill in the format shown by the sample. Then for each time period of a call, print in one line the beginning and ending time and date (dd:hh:mm), the lasting time (in minute) and the charge of the call. The calls must be listed in chronological order. Finally, print the total charge for the month in the format shown by the sample.
Sample Input:
10 10 10 10 10 10 20 20 20 15 15 15 15 15 15 15 20 30 20 15 15 10 10 10
10
CYLL 01:01:06:01 on-line
CYLL 01:28:16:05 off-line
CYJJ 01:01:07:00 off-line
CYLL 01:01:08:03 off-line
CYJJ 01:01:05:59 on-line
aaa 01:01:01:03 on-line
aaa 01:02:00:01 on-line
CYLL 01:28:15:41 on-line
aaa 01:05:02:24 on-line
aaa 01:04:23:59 off-line
Sample Output:
CYJJ 01
01:05:59 01:07:00 61 $12.10
Total amount: $12.10
CYLL 01
01:06:01 01:08:03 122 $24.40
28:15:41 28:16:05 24 $3.85
Total amount: $28.25
aaa 01
02:00:01 04:23:59 4318 $638.80
Total amount: $638.80
分析:将给出的数据先按照姓名排序,再按照时间的先后顺序排列,这样遍历的时候,前后两个名字相同且前面的状态为on-line后面一个的状态为off-line的就是合格数据~
注意:【关于最后一个测试点】计算费用从00:00:00到dd:hh:mm计算可以避免跨天的问题,比如01:12:00到02:02:00
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
#include <iostream> #include <map> #include <vector> #include <algorithm> using namespace std; struct node { string name; int status, month, time, day, hour, minute; }; bool cmp(node a, node b) { return a.name != b.name ? a.name < b.name : a.time < b.time; } double billFromZero(node call, int *rate) { double total = rate[call.hour] * call.minute + rate[24] * 60 * call.day; for (int i = 0; i < call.hour; i++) total += rate[i] * 60; return total / 100.0; } int main() { int rate[25] = {0}, n; for (int i = 0; i < 24; i++) { scanf("%d", &rate[i]); rate[24] += rate[i]; } scanf("%d", &n); vector<node> data(n); for (int i = 0; i < n; i++) { cin >> data[i].name; scanf("%d:%d:%d:%d", &data[i].month, &data[i].day, &data[i].hour, &data[i].minute); string temp; cin >> temp; data[i].status = (temp == "on-line") ? 1 : 0; data[i].time = data[i].day * 24 * 60 + data[i].hour * 60 + data[i].minute; } sort(data.begin(), data.end(), cmp); map<string, vector<node> > custom; for (int i = 1; i < n; i++) { if (data[i].name == data[i - 1].name && data[i - 1].status == 1 && data[i].status == 0) { custom[data[i - 1].name].push_back(data[i - 1]); custom[data[i].name].push_back(data[i]); } } for (auto it : custom) { vector<node> temp = it.second; cout << it.first; printf(" %02d\n", temp[0].month); double total = 0.0; for (int i = 1; i < temp.size(); i += 2) { double t = billFromZero(temp[i], rate) - billFromZero(temp[i - 1], rate); printf("%02d:%02d:%02d %02d:%02d:%02d %d $%.2f\n", temp[i - 1].day, temp[i - 1].hour, temp[i - 1].minute, temp[i].day, temp[i].hour, temp[i].minute, temp[i].time - temp[i - 1].time, t); total += t; } printf("Total amount: $%.2f\n", total); } return 0; } |